關于同意本溪北營鋼鐵集團股份變更螺紋鋼產品標牌及表面標識的公告
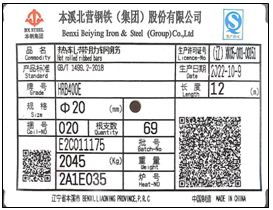
為適應市場需求,提升品牌形象,并進一步規范產品標識管理,根據《中華人民共和國產品質量法》、《鋼鐵產品標識標準》等相關法律法規及行業標準,經本溪北營鋼鐵集團股份有限公司(以下簡稱“公司”)研究決定,現就公司螺紋鋼產品標牌及表面標識變更事宜公告如下:
一、 變更內容
自本公告發布之日起,公司將對所生產的螺紋鋼產品的標牌(即產品出廠隨附的紙質或塑料質地的標識牌)及產品表面標識(即直接軋制或噴涂于鋼材表面的標記)進行系統性設計與變更。新的標識體系將包含但不限于以下核心信息:
- 公司注冊商標及企業名稱;
- 產品牌號、規格、執行標準;
- 爐批號、生產日期、重量等追溯信息;
- 產品質量等級及認證標識(如適用);
- 增加防偽技術元素,以保障消費者權益。
二、 設計原則與目標
本次標識設計遵循以下原則:
- 合規性:嚴格符合國家及行業最新標準與規范。
- 清晰性:標識內容清晰、準確、易讀,便于識別與追溯。
- 統一性:實現標牌與表面標識在核心信息上的統一,強化品牌整體形象。
- 防偽性:引入先進的防偽技術,有效遏制假冒偽劣產品。
- 美觀性:設計簡潔、大方,體現公司產品的專業與可靠品質。
三、 實施安排
- 過渡期:自【請在此處插入具體起始日期】起至【請在此處插入具體截止日期】為產品標識變更過渡期。過渡期內,新舊標識的產品可能并存于市場。
- 全面啟用:自【請在此處插入具體起始日期】起,所有新出廠的螺紋鋼產品將全面啟用新的標牌及表面標識。
- 資料更新:公司相關的產品說明書、質量證明書、宣傳材料及官方網站信息將同步更新。
四、 對客戶及合作伙伴的提示
- 請廣大客戶、經銷商及合作伙伴知悉上述變更,并在采購、驗收及使用過程中注意識別新標識。
- 新舊標識變更不影響產品本身的質量、性能及執行標準。公司所有螺紋鋼產品均嚴格按照國家標準組織生產,質量持續穩定可靠。
- 如有任何疑問,請致電本公司客戶服務熱線【請在此處插入聯系電話】或咨詢當地經銷商。
五、 其他
本次標識變更是公司品牌建設與質量管理工作的重要舉措,旨在為客戶提供更優質、更可靠的產品與服務。感謝廣大客戶與社會各界長期以來的支持與信任。
特此公告。
本溪北營鋼鐵集團股份有限公司
【請在此處插入公告發布日期】
如若轉載,請注明出處:http://www.1122x.cn/product/7.html
更新時間:2026-06-19 12:38:33









